Cloud storage for enterprise applications operates at a fundamentally different scale and architectural level than consumer file storage services. While platforms like Dropbox and Google Drive focus on individual users storing and sharing documents, enterprise object storage platforms provide the infrastructure layer that powers websites, applications, data lakes, backup systems, and machine learning pipelines — often storing billions of objects across petabytes of capacity without any interaction from end users browsing folders. Amazon Simple Storage Service (Amazon S3), launched in March 2006, pioneered and defined the cloud object storage category and continues to remain the most widely adopted cloud storage infrastructure service in the world. As a foundational service within Amazon Web Services (AWS), S3 provides virtually unlimited and elastic storage capacity with 99.999999999% (eleven nines) durability, meaning that the probability of losing a stored object is extraordinarily low — designed to sustain the simultaneous loss of data in two facilities without data loss.
S3’s broader significance extends beyond raw storage capacity. The platform introduced the revolutionary pay-as-you-go cloud pricing model that fundamentally transformed enterprise IT economics, pioneered storage class tiering that optimizes cost based on access patterns, and established the RESTful API approach to cloud storage interaction that influenced nearly virtually every subsequent cloud storage service. Understanding S3’s architecture, storage classes, security model, and integration capabilities helps organizations evaluate whether this foundational and market-leading cloud infrastructure platform meets their specific data storage requirements or whether alternative object storage providers offer advantages for specific use cases. This comprehensive review covers S3 from an architectural and capability perspective, providing the comprehensive technical understanding needed for informed evaluation rather than step-by-step implementation guidance.
Object Storage Architecture
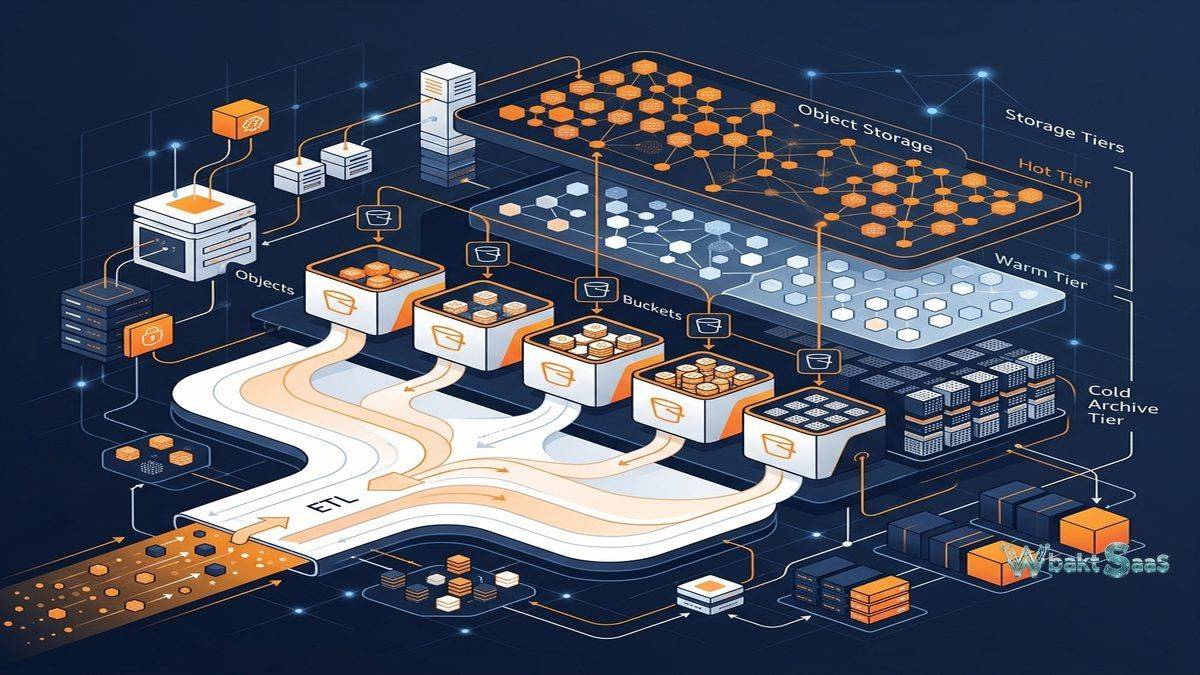
S3 organizes data as objects within buckets. each individual object consists of data (the file content), metadata (system and user-defined key-value pairs), and a unique key (identifier) within its bucket. Unlike hierarchical file systems with directories and subdirectories, S3 uses a flat namespace where the key path (e.g., “projects/2024/reports/quarterly.pdf”) creates the appearance of folder structure without actual directory hierarchy. This flat architectural design enables massive scalability — individual buckets can store virtually unlimited objects without the performance degradation that traditional hierarchical file systems experience at massive scale. Individual objects can range from 0 bytes to 5 terabytes in size, with multipart upload enabling highly efficient transfer of large objects through efficient parallel upload streams.
Storage Classes
S3 provides multiple storage classes optimized for different access patterns and cost requirements. S3 Standard provides highly durable, high-performance storage for frequently accessed data with millisecond access latency. S3 Standard-IA (Infrequent Access) provides lower storage costs for data accessed less frequently, with retrieval fees that incentivize appropriate usage. S3 One Zone-IA provides even lower costs by storing data in a single availability zone rather than across multiple zones. S3 Glacier Instant Retrieval provides cost-effective archive storage with millisecond retrieval for quarterly-accessed data. S3 Glacier Flexible Retrieval provides very low-cost archive storage with configurable retrieval times ranging from minutes to hours. S3 Glacier Deep Archive provides the lowest-cost storage for rarely accessed data with retrieval times of 12-48 hours. S3 Intelligent-Tiering automatically moves objects between access tiers based on observed usage patterns, optimizing costs without manual management.
Lifecycle Management
Lifecycle policies intelligently automate storage class transitions and object deletion based on configurable rules. Organizations define policies that transition objects from Standard to Standard-IA after 30 days, to Glacier after 90 days, and to Deep Archive after 365 days — automatically optimizing storage costs as data ages without manual intervention. Expiration rules automatically delete objects after specified retention periods. Lifecycle management is essential for controlling costs in large-scale storage environments where manually managing millions or billions of objects across storage classes would be impractical. Flexible filter-based rules apply lifecycle actions to subsets of objects based on key prefixes, tags, or object size thresholds.
Security and Access Control
S3 provides comprehensive security through multiple complementary mechanisms. Bucket policies define comprehensive access rules at the bucket level using JSON policy documents. IAM (Identity and Access Management) policies provide granular control over user and service access to S3 resources. Access Control Lists (ACLs) provide legacy object-level permissions. S3 Block Public Access provides account-wide and bucket-level controls that prevent accidental public exposure of stored data — addressing one of the most common cloud storage security risks. Server-side encryption (SSE) encrypts data at rest using Amazon-managed keys (SSE-S3), AWS Key Management Service keys (SSE-KMS), or customer-provided keys (SSE-C). Client-side encryption enables encrypting data before upload for maximum customer security control. S3 Access Points create dedicated named network endpoints with distinct access policies, simplifying shared data set access management for applications with different access requirements.
Versioning
S3 versioning preserves every version of every object stored in a versioned bucket. When objects are overwritten or deleted, all previous versions remain fully accessible and recoverable. Versioning protects against accidental deletion, application errors, and data corruption by maintaining complete version histories. MFA Delete additionally requires multi-factor authentication for permanent version deletion, preventing unauthorized or accidental permanent data loss. Object Lock provides WORM (Write Once Read Many) protection that prevents objects from being deleted or overwritten for specified retention periods — required for regulatory compliance in financial services, healthcare, and government contexts.
Replication
S3 replication automatically copies objects between buckets. Cross-Region Replication (CRR) copies objects to buckets in different AWS regions, providing geographic redundancy, significantly lower-latency access for distributed users, and compliance with data residency requirements. Same-Region Replication (SRR) copies objects between buckets within the same region for access logging aggregation, compliance requirements, and organizational data distribution. Replication can be configured for entire buckets, specific prefixes, or objects matching specific tags, providing granular control over what data is replicated and where.
Data Analytics and Query
S3 deeply integrates with AWS analytics services for querying and analyzing stored data without requiring data movement to separate analytics platforms. S3 Select and Glacier Select retrieve subsets of object data using SQL expressions, significantly reducing data transfer by filtering at the storage layer. Amazon Athena queries data directly in S3 using standard SQL without any data loading or transformation. Amazon Redshift Spectrum extends data warehouse queries to S3-stored data. These capabilities transform S3 from passive data storage into an active data platform that supports analytics, machine learning, and data processing workloads directly on stored data.
Event Notifications and Integration
S3 event notifications automatically trigger automated actions when objects are created, deleted, or transitioned. Events can directly invoke AWS Lambda functions for serverless data processing, publish to Amazon SNS topics for notification delivery, and send messages to Amazon SQS queues for asynchronous processing. Event-driven architectures use S3 as the data ingestion layer that triggers downstream processing — image uploads triggering thumbnail generation, document uploads triggering text extraction, and data file uploads automatically triggering ETL processing pipelines.
Transfer and Migration
S3 Transfer Acceleration uses CloudFront edge locations to accelerate long-distance transfers to S3 buckets. AWS DataSync provides high-performance automated data transfer between on-premises storage and S3. AWS Snow Family provides ruggedized physical devices for transferring petabyte-scale datasets to S3 when network-based transfer is impractical. AWS Transfer Family provides fully managed SFTP, FTPS, and FTP services for transferring files to S3 using existing file transfer workflows and protocols.
Monitoring and Analytics
S3 Storage Lens provides organization-wide visibility into storage usage, activity trends, and cost optimization opportunities across all S3 buckets. S3 Inventory generates scheduled reports listing stored objects and their metadata for auditing and compliance reporting. S3 server access logging records detailed information about requests made to S3 buckets for security analysis, access auditing, and compliance monitoring. CloudWatch metrics provide real-time monitoring of bucket-level operations, errors, and performance metrics.
Batch Operations
S3 Batch Operations perform large-scale operations across billions of objects with a single request. organizations use batch operations to copy objects between buckets or accounts, invoke Lambda functions on every object, modify access control lists, restore archived objects, and apply or remove tags at scale. Without batch operations, performing these actions on millions of objects would require custom scripting, error handling, retry logic, and progress tracking. Batch operations provide fully managed, reliable execution with progress reporting, failure handling, and completion notifications that simplify large-scale content management tasks.
S3 Express One Zone
S3 Express One Zone provides single-digit millisecond data access for the most performance-sensitive applications, delivering up to 10x faster performance than S3 Standard. Directory buckets in Express One Zone organize data using directory hierarchy structures optimized for low-latency access. This specialized storage class serves workloads requiring consistent, extremely low-latency access — machine learning training data, financial modeling computations, interactive analytics, and real-time data processing applications where storage access latency directly impacts application performance.
Performance Optimization
S3 automatically and transparently scales to handle thousands of requests per second per prefix without performance degradation. Multipart upload enables parallel upload of large objects, improving overall throughput by transferring multiple parts simultaneously. Byte-range fetches similarly enable parallel download of different portions of large objects. Transfer Acceleration intelligently routes uploads through CloudFront edge locations for improved transfer speeds across geographic distances. For applications requiring the highest throughput, S3 can handle over 5,500 GET and 3,500 PUT requests per second per prefix, with performance scaling linearly across prefixes for virtually unlimited aggregate throughput.
Cost Optimization Strategies
Effective S3 cost management involves multiple strategies beyond storage class selection. S3 Intelligent-Tiering eliminates manual tier management by automatically moving objects between access tiers based on observed patterns. Lifecycle policies transition aging data to progressively lower-cost storage classes automatically. S3 Analytics provides data-driven storage class analysis recommendations based on actual access patterns. Requester Pays bucket configurations transfer data transfer costs to the requesting party rather than the bucket owner — useful for shared datasets and public research data. Storage Lens cost efficiency metrics identify optimization opportunities across the organization’s storage footprint.
Compliance and Governance
S3 Object Lock provides immutable storage for regulatory compliance, supporting both Governance mode (which can be overridden by privileged users) and Compliance mode (which cannot be overridden by any user, including the root account). Legal Hold prevents object deletion independently of retention periods for litigation-related preservation. AWS CloudTrail logs all S3 API calls for audit trails. S3 supports major compliance frameworks including SEC Rule 17a-4, HIPAA, PCI DSS, FedRAMP, SOC, and ISO certifications. Bucket tagging and access policies enable implementing organizational data governance frameworks that control data classification, retention, and access across the storage infrastructure.
Common Use Cases
Application Data: Web and mobile applications use S3 for storing user-generated content, application assets, configuration data, session state, and media files across scalable, distributed architectures that serve millions of concurrent users.
Data Lakes: Organizations build enterprise data lakes on S3, centralizing structured and unstructured data from databases, IoT devices, applications, and third-party sources for analytics, machine learning, and business intelligence processing.
Backup and Disaster Recovery: enterprise and mid-market backup systems use S3 and S3 Glacier for off-site backup storage with lifecycle-driven cost optimization, cross-region replication for geographic disaster recovery, and Object Lock for immutable backup protection.
Static Website Hosting: S3 hosts static websites including HTML, CSS, JavaScript, images, and video directly from S3 buckets with CloudFront CDN integration for low-latency global content delivery to users worldwide.
Archive and Compliance: Financial institutions, healthcare organizations, and government agencies archive regulatory-required data in S3 Glacier with Object Lock for WORM compliance, automated retention policies, and legal hold capabilities that meet industry-specific regulatory requirements.
Media and Content Delivery: Media companies store and serve video, audio, and image content from S3 with CloudFront CDN providing low-latency global content delivery, adaptive bitrate streaming, and content protection through signed URLs.
Machine Learning: Data science teams store training datasets, model artifacts, and inference results in S3, leveraging its integration with Amazon SageMaker and other ML services for the complete machine learning workflow from data preparation through model deployment.
Pricing
S3 pricing varies by storage class, region, data volume, request type, and data transfer. Storage costs are calculated per GB per month with declining per-GB rates at higher volumes. Request costs apply per 1,000 requests with rates varying by request type (PUT, GET, LIST). Data transfer out of S3 incurs standard per-GB charges, while data transfer in is free. S3 Intelligent-Tiering includes monitoring and automation fees. The generous free tier includes 5 GB of Standard storage, 20,000 GET requests, and 2,000 PUT requests per month for the first year for new AWS accounts.
Pricing varies by region and changes periodically. Please verify current pricing on the official AWS S3 pricing page before making architecture decisions.
Limitations
- Not consumer-friendly: S3 is infrastructure-level storage designed for developers and IT teams. It does not provide the intuitive, user-friendly file management interfaces that platforms like Dropbox or Google Drive offer for everyday users.
- Cost complexity: S3 pricing involves multiple cost dimensions (storage, requests, retrieval, transfer) that can make accurate cost prediction challenging without careful ongoing analysis and monitoring.
- AWS ecosystem dependency and lock-in: Deep integration with AWS services creates significant value but also creates migration complexity for organizations that may want to move to competing cloud platforms.
- Configuration complexity: Properly configuring S3 security, lifecycle policies, and replication requires significant technical expertise. Misconfiguration — particularly with security settings — can create serious data exposure risks.
- Eventual consistency: While S3 now provides strong consistency for all operations, understanding the distributed systems architecture remains important for application developers building on S3.
Summary
Amazon Amazon S3 provides the foundational cloud object storage platform that powers a truly significant portion of the internet’s infrastructure — from startup applications to enterprise data lakes to some of the world’s largest websites. The platform’s virtually unlimited scalability, eleven-nines durability, multiple storage classes for cost optimization, and deep AWS ecosystem integration create an object storage foundation that serves practically any data storage requirement at virtually any scale.
S3’s comprehensive storage class architecture — from Standard for frequently accessed data through Glacier Deep Archive for long-term compliance archives — enables organizations to optimize storage costs across the entire data lifecycle with automated lifecycle policies that transition data between tiers based on configurable rules and access patterns.
Enterprise object storage platforms including Amazon S3, Google Cloud Storage, Microsoft Azure Blob Storage, and Wasabi each provide enterprise cloud storage infrastructure with different pricing structures, capabilities,, geographic availability, and ecosystem integrations. S3’s advantages center on market maturity, AWS ecosystem integration depth, storage class breadth, tooling ecosystem, and the reliability that comes from operating the world’s largest cloud storage infrastructure at unmatched global scale. Organizations evaluating object storage should consider their existing cloud platform investments, geographic requirements, and their specific workload characteristics when comparing infrastructure storage options.
Features, pricing, and availability discussed in this review reflect information available at the time of writing. Cloud infrastructure services evolve continuously, and details may have changed since publication. Please verify current information directly on the official AWS S3 website. WBAKT SaaS is an independent review platform with no affiliate relationships with any cloud provider mentioned in this article.
For related cloud storage tools, see our reviews of Wasabi Object Storage, Backblaze Backup, and Google Drive.